


Multicloud is Madness!!!!
Your organization is doing a poor job protecting the one cloud you have. Why in heaven’s name would you want to deploy into another cloud? In this two-part blog post, we’ll cover details from my HackCon 2024 talk “Chris Farris in the MultiCloud of Madness” (slides). Part one is here, and it covers all the weirdness between the three major hyperscalers - AWS, Azure, and GCP. The second part will provide checklists to help you establish Minimally Viable Cloud Governance in each cloud.
There are generally two schools of Multicloud thought:
“Our workloads must be instantly portable to another cloud provider. We cannot depend on Amazon or Microsoft not to raise prices on us." –An executive who has experienced an Oracle Audit.
“We use AWS for our customer-facing application, Azure for our back office finance systems, and Google’s Big Query for our data analytics team." –An executive who uses the right cloud for the right job.
The first school was typical in the early days of the cloud. The public cloud was just another data center with all the same primitives - compute, storage, networking, and some managed relational database. You can play providers off each other for the best price and golf outings. Meanwhile, your engineers are clicking madly in the console to set things up so they can run some random terraform modules they found online.
The second school of thought is more common now. With OpenAI’s lead in Generative AI, companies in AWS are looking at Azure. Google’s BigQuery has been a leading data warehouse tool for many years. Plus, if you have a website and marketing department, you use GCP to manage ad buying, Google Analytics, and your official YouTube channel.
There are other reasons to be multicloud, such as:
- SaaS Provider - you need to be where your customers are. This is a valid reason to be multicloud, and your customers expect excellence in each. Plan your hiring accordingly.
- Mergers and Acquisitions - congrats, the company your management just decided to buy is big into a provider that’s not your main one. Hopefully, their cloud security experts don’t get swept away in the post-acquisition layoffs or payouts.
But I’ll propose that You are multi-cloud whether you like it or not. You probably have workloads in all three clouds. If you think otherwise, you’re probably deluding yourself. Most companies have a primary cloud and then the other forgotten clouds.
Problems with being Multicloud are:
- Cost - If you divide your cloud spending three ways, you bring a smaller commitment number to the negotiating table. You’ll get a bigger discount, pushing most of your spending to one provider, and only use the others for specific niche use cases.
- Security & Identity - As we’ll see below, security and identity are very different in each cloud. You need to staff a team that knows the nuances of all three providers and ensure that your identities are configured so you actually own your cloud resources.
- People - All of this goes to people. The more clouds you run, the more experts you need to know how they work under the hood.
All Clouds are not the same
Tenancy
One of the core concepts of cloud computing is the idea of multi-tenancy: the provider owns the hardware, and multiple customers share those resources. Implementing Multi-tenancy is the core security function of the cloud.
How the different providers implement their tenancy impacts your thinking about security.
GCP
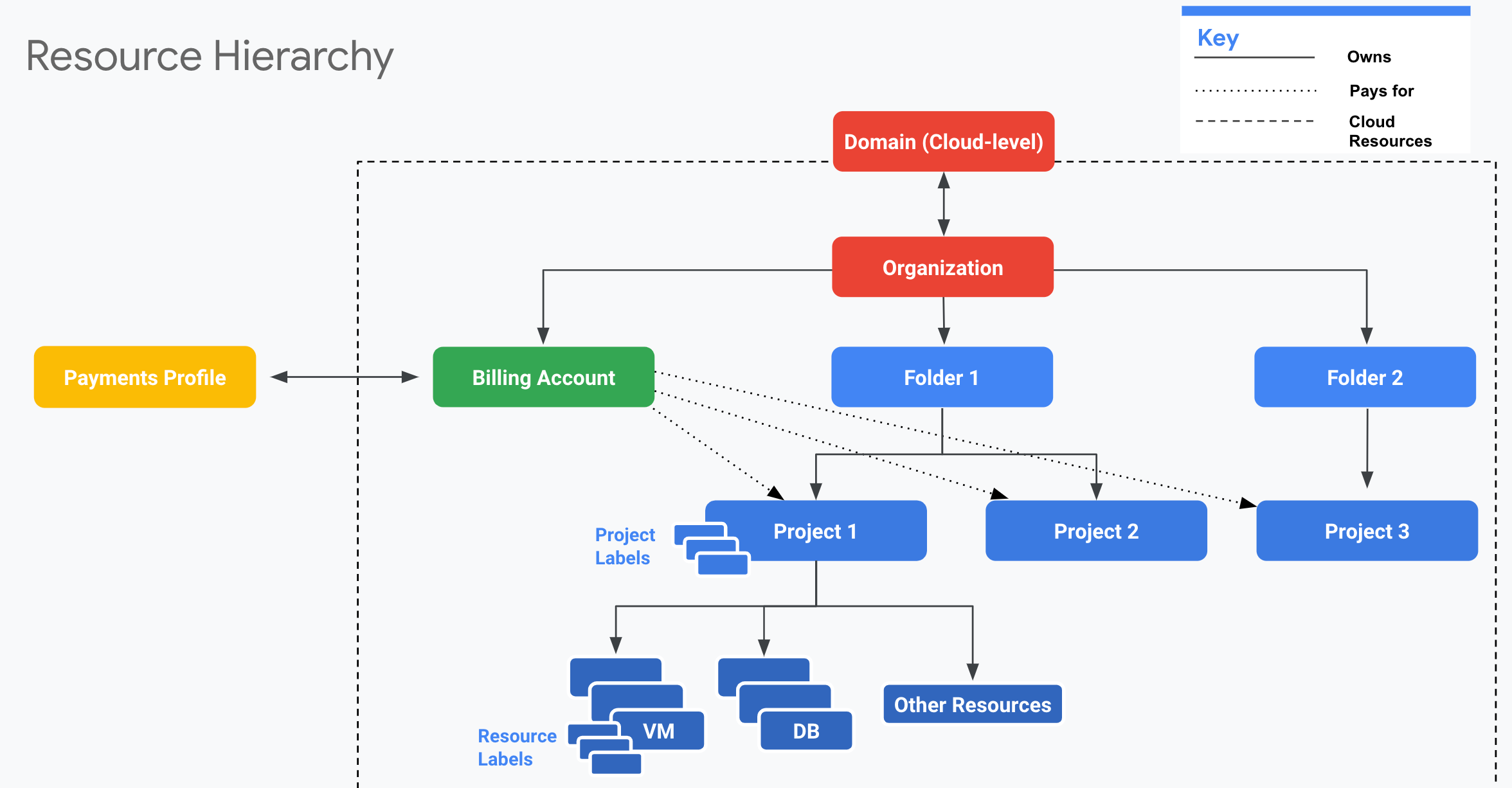
With GCP, the “customer” is the Domain: “primeharbor.com”. This is where both Google Workspace and Google Cloud Platform services reside. All Google Cloud resources are part of an Organization.
Inside the organization, you can spin up projects for your compute workloads. Projects can (optionally) be inside folders with access and policies applied on a per-organization, per-folder, or per-project basis.
For a Project to run workloads that will incur costs, the project must be attached to a Billing Account. An Organization can have one or more Billing Accounts. A project can also be attached to a billing account that’s part of another organization.
The following shows the full relationship between Google Workspace (Domain), GCP (Organization, Folders, Project), and the Billing Account:
Azure
With Azure, the “customer” is the Azure AD (now Entra ID) tenant. Rather than being tied to a DNS domain name like GCP, Azure’s concept of the customer is tied to this Directory. Typically, that directory is tied to a domain, like “primeharbor.net”.
Subscriptions are then created under this tenant to run workloads.
To run workloads that cost money, subscriptions must be tied to a Billing Account. Each Billing Account has an Agreement type, which are the legal/commercial terms for the subscriptions.
For enterprises under an Enterprise Agreement, there is also an Enterprise Agreement Portal that lists all the subscriptions. In larger organizations, this is the best way for a security person to track all the subscriptions, as they may not be visible to you by default.
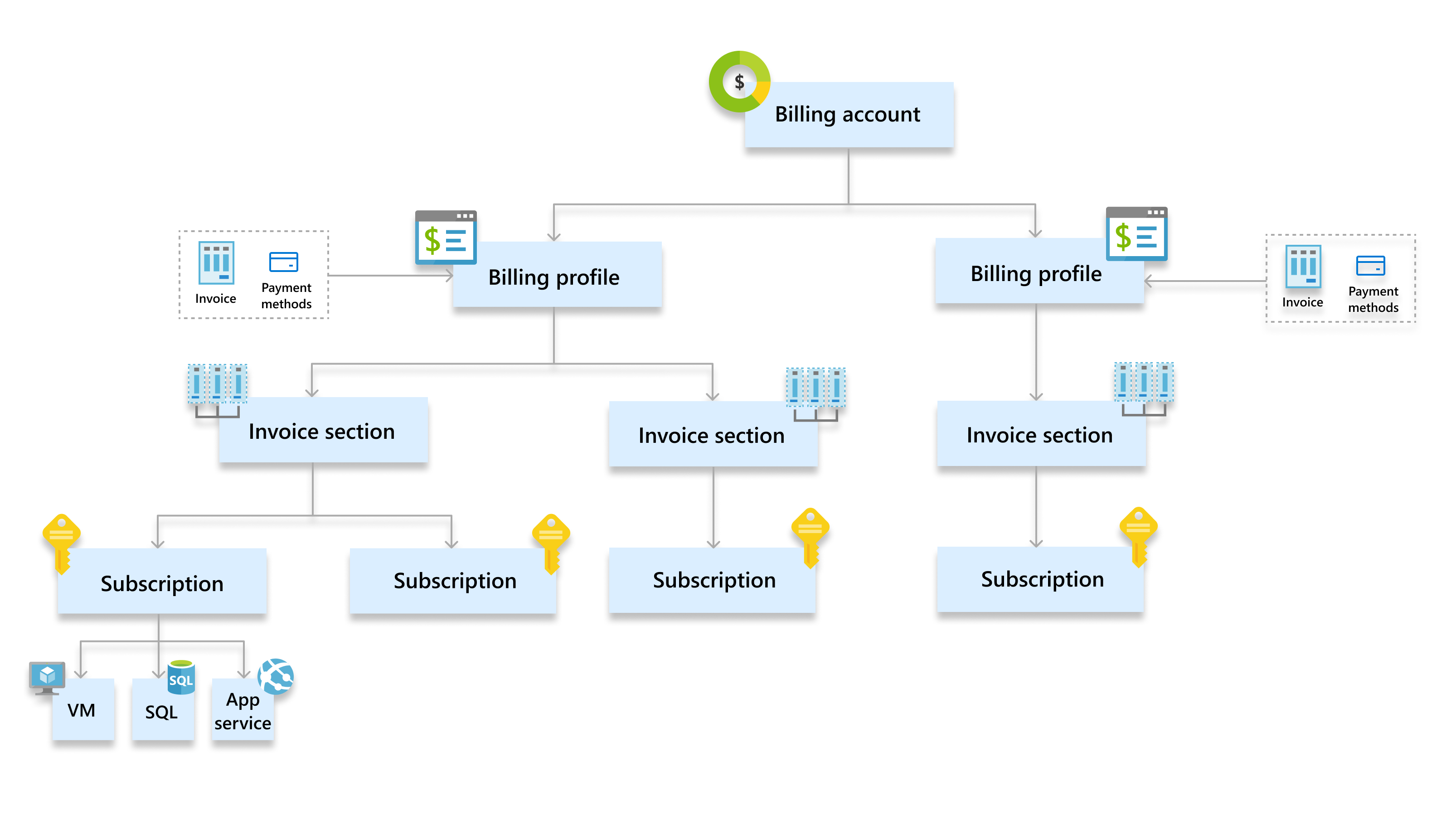
Azure has another governance construct called Management Groups. These are not enabled by default. Like the folder structure in GCP, Management Groups allow you to organize subscriptions by hierarchy. You can apply Azure Blueprints to the Tenant Root Groupor to subgroups underneath. Blueprints are resource definitions that are expected to be in every subscription. Their purpose is to ensure that when a subscription is created (or when the blueprint is applied), the subscription complies with all the organization’s cloud security & governance standards.
AWS
With AWS, the primary tenancy boundary is the AWS Account. AWS Accounts may be grouped under a Consolidating Billing account or a member of an AWS Organization. Regardless of Organization membership or who is paying for the account, each AWS Account is a separate AWS Customer, represented by the Root User.
As AWS has evolved, more capabilities have been added to AWS Organizations, allowing it to do things to the child account. These are implemented via Service Linked Roles, and AWS Services managed by one account in the organization can act on that service in other accounts. From a customer perspective, There is no implicit trust of identities across accounts. Every actor’s principal is scoped only to the account the principal resides in. All cross-account trusts must be explicitly configured. There is no concept of a single identity having native access to multiple accounts like Azure or GCP.
Identity
The source of identity in the three clouds is different, too. Identity can generally be broken down into two components: Identities for Humans and Identities for Resources (either internal or external).
Azure
With Azure, access to subscriptions is via the Azure AD identity. There are Users for people and Service Principals for systems. Often, the same identity used for Office 365 is used for accessing Azure, and many 365 users can open up portal.azure.com while logged into Exchange and have some ability to poke around in Azure AD.
External users can be added to a company’s Azure AD to access both SaaS and Azure Cloud resources.
Resources use Azure Service Principals for access to the Azure APIs. These are App registrations in the console. These service principals can have either Client secrets (long-term, bad!) or OIDC Federated credentials.
Long-term credentials consist of the appId, password/secret, and (AzureAD) tenant:
{
"appId": "565aef2b-e892-4ab9-b272-3658b23e581c",
"displayName": "azure-cli-2024-01-07-13-41-17",
"password": "ejaREDACTED",
"tenant": "a83c74c3-7570-f74e-94c2-4bc9b3e0a510"
}
GCP
With GCP, access is granted via a person’s Google Workspace account. If Google Workspace isn’t enabled (as it’s a licensed feature), Google has a free Cloud Identity account that can be used. The only difference between a Workspace and Cloud Identity account is access to tools like Google Docs, Google Sheets, and Gmail.
Google Identities are managed via the admin.google.com portal. Access to this portal requires SuperAdmin permissions and is granted outside of the Google Cloud Platform IAM. If you’re charged with protecting GCP, you also need to look at the security settings in the admin.google.com portal and how Super Admin accounts are secured.
System access in GCP can happen via either Service Accounts or Workload identity federation. Service Accounts can be attached to resources, or you can generate Service account keys, which are long-term credentials that someone will eventually commit to GitHub and ruin your day.
The key looks like:
{
"type": "service_account",
"project_id": "pht-sandbox",
"private_key_id": "44a65c6cb73fba5babfb6c6012a027e798d6c053",
"private_key": "-----BEGIN PRIVATE KEY-----\nTHISISNOTAREALPRIVATEKEYTHISISJUSTATRIBUTE==\n-----END PRIVATE KEY-----\n",
"client_email": "test-account1@pht-sandbox.iam.gserviceaccount.com",
"client_id": "116904192699609924808",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/test-account1%40pht-sandbox.iam.gserviceaccount.com",
"universe_domain": "googleapis.com"
}
AWS
AWS’s dividing line between humans and resources is much less clear. AWS has IAM Users and IAM Roles. IAM Users are distinct identities that exist on a per-account basis. They can have both a LoginProfile for access to the AWS web console and Access Keys for access to the APIs and CLI.
IAM Roles also exist only in an account, but they are meant to be assumed by something other than themselves. Role assumption can occur via a service (Lambda, EC2) or an external identity provider (Okta, AzureAD, etc.).
IAM Users have long-term access keys, and Roles have short-term access keys that expire at a set time.
In AWS, Users and Resources can use either. Long-term access keys can be used on an instance, while people can assume Roles.
AWS has a service, Identity Center, that can provide human access to multiple accounts in an organization via IAM Roles pushed to each account via the Organizations service. Identity Center can be its own identity store or leverage an external identity store like Google, Azure, or Okta.
The ClusterFuck of Consumer Identities
All three cloud providers have roots outside of basic IaaS Cloud Computing. All three have consumer offerings around SaaS and retail. This means that not all identities with access to your environment are yours!
In AWS, the account is owned by the root email address, regardless of the organization or who pays for it. For the longest time, the root email and password of the AWS account were also the root email and password for the associated retail account. AWS has finally broken that link, but it’s probably still in place with older accounts.
With GCP, users can create their.name@yourcompany.com email addresses. Even though the address uses your domain, Google considers the account to belong to the employee. You have no enterprise control over it, and Google’s terms of service are the public free terms, meaning they can use whatever they see for advertising.
Microsoft also has the concept of a retail account that can be used for gaming, outlook, etc. While it’s less common for a company not to have a properly configured Azure Tenant, a pure Google shop could see itself with consumer Microsoft accounts it doesn’t control.
Logging
Cloud logging can take many forms. There’s the logging from instances/VMs, load balancers, containers, CDNs, and more. However, the critical logging type that should be set up for every cloud is the Cloud Control-Plane API logging. This is known as Audit Logs in Azure, CloudTrail in AWS, and Activity Logs in GCP.
These logs are critical for any form of cloud incident response. At some point in your cloud career, sensitive credentials like Access Keys or Service Accounts will find their way into a threat actor’s hands, and these are the audit logs that will tell you what that threat actor did and what they changed.
AWS
In AWS, CloudTrail is the cloud-plane API logging service. Every call made by an IAM User, IAM Role, or AWS Service will be logged in CloudTrail (exception are data events).
By default, mutating (aka write) events are logged in each account in each region. To capture read events, you must create a CloudTrail Trail and write those events to an S3 Bucket. This can be done at the AWS Organizational level by creating a Trail in the Organization Management Account and selecting “Apply trail to my organization”. AWS provides the first Trail for free; additional trails cost money.
By default, a CloudTrail trail only records Management Events. To record data access events using AWS Credentials, you must explicitly define the data events you want to record. Because of the potential volume, these Data Events are not free, and care should be taken before blindly enabling them.
This is what a generic CloudTrail event looks like:
{
"awsRegion": "us-east-1",
"eventName": "CreateBucket",
"eventSource": "s3.amazonaws.com",
"eventTime": "2019-06-09T15:37:18Z",
"eventType": "AwsApiCall",
"recipientAccountId": "123456789012",
"requestParameters": {},
"responseElements": null,
"sourceIPAddress": "192.168.357.420",
"userAgent": "[S3Console/0.4, aws-internal/3 aws-sdk-java/1.11.526
Linux/4.9.152-0.1.ac.221.79.329.metal1.x86_64 OpenJDK_64-Bit_Server_VM/25.202-b08
java/1.8.0_202 vendor/Oracle_Corporation]",
"userIdentity": {
"accessKeyId": "ASIATFNORDFNORDAZQ",
"accountId": "123456789012",
"arn": "arn:aws:sts::123456789012:assumed-role/assume-rolename/first.last@company.com",
"type": "AssumedRole"
}
}
A few key elements from an incident response perspective are:
eventName- This is the API Call madeeventSource- This is the AWS service (ec2, s3, lambda, etc)sourceIPAddress- IP address the call came from. It’s either an IP, or an AWS service likecloudformation.amazonaws.comuserIdentity.arn- Depending on type, the attributes of userIdentity change, but the arn is always presentuserIdentity.type- TypicallyIAMUserorAssumeRolerecipientAccountId- AWS Account ID the event was for. In this post, they will all be 123456789012
requestParameters will change based on the API call. Sometimes, there are useful filters in there.
Azure
Azure Monitor is the service that processes the cloud-plane API events in Azure. The events themselves are Activity Logs. The activity logs are visible in the console under each service for 90 days by default. If you want to persist the logs somewhere for IR or compliance reasons, you need to create a Diagnostic setting (intuitive, right?!?!). These are on a per-subscription basis. You must also create a Diagnostic Setting on your Azure AD tenant to capture authentication and user information.
Having not learned from the Chinese Hack of the US State Department, Microsoft still does pay-for-play with basic security like sign-in logs:

Blueprints can be leveraged to ensure the Diagnostic Setting is in place for all subscriptions. In what I can only assume is a request from Cozy Bear, Azure doesn’t actually log read-only events, only mutating events.
An Azure AD log event looks like
{
"time": "2024-01-07T19:13:28.2829479Z",
"resourceId": "/tenants/a83c74c3-7570-f74e-94c2-4bc9b3e0a510/providers/Microsoft.aadiam",
"operationName": "Add service principal", <- Free form text? really?
"operationVersion": "1.0",
"category": "AuditLogs",
"tenantId": "a83c74c3-7570-f74e-94c2-4bc9b3e0a510",
"correlationId": "b1fe068d-2dc0-4fa8-8725-c272070f8906",
"Level": 4,
"properties": {
"id": "Directory_b1fexxxxx",
"category": "ApplicationManagement",
"correlationId": "b1fe068d-2dc0-4fa8-8725-c272070f8906",
"result": "success",
"resultReason": "",
"activityDisplayName": "Add service principal", <- Detection Engineers hate this one trick!
"activityDateTime": "2024-01-07T19:13:28.2829479+00:00",
"loggedByService": "Core Directory",
"operationType": "Add", <- CRUD
"userAgent": null,
"initiatedBy": {
"user": {
"id": "xxxx-xxxx-xxxx-xxxx-xxxxxxxxx",
"displayName": null,
"userPrincipalName": "chris@primeharbor.net", <- Hey that's me!
"ipAddress": "",
"roles": []
}
},
"targetResources": [
{
"id": "e42a5c8f-b2c8-49c1-9e77-6e46d54cc556",
"displayName": "azure-cli-2024-01-07-19-13-22", <- my name of the service principal
"type": "ServicePrincipal",
"modifiedProperties": [], <- changes made
"administrativeUnits": []
}
],
"additionalDetails": [
{
"key": "User-Agent",
"value": "python/3.11.5 (Linux-6.4.16-linuxkit-x86_64-with-glibc2.35) AZURECLI/2.55.0 (DEB)"
},
{
"key": "AppId",
"value": "1bfc655b-7732-44e9-92a9-e836357f5400"
}
]
}
}
As for Azure itself, the events come in pairs - a Start and a Succeeded resultType:
{
"RoleLocation": "Canada Central", <- Not sure why my role is in Canada eh?
"time": "2024-01-07T20:16:23.3732085Z",
"resourceId": "/SUBSCRIPTIONS/815322B7-F234-4156-96D1-927E59ACD96B/PROVIDERS/MICROSOFT.INSIGHTS/DIAGNOSTICSETTINGS/LOGGING",
"operationName": "MICROSOFT.INSIGHTS/DIAGNOSTICSETTINGS/WRITE", <- Why are you YELLING?
"category": "Administrative",
"resultType": "Start",
"durationMs": "0",
"callerIpAddress": "192.168.357.420",
"correlationId": "10019937-0818-4529-8c57-0f129d43be80",
"identity": {
"authorization": {
"scope": "/subscriptions/815322b7-f234-4156-96d1-927e59acd96b/providers/microsoft.insights/diagnosticSettings/logging",
"action": "microsoft.insights/diagnosticSettings/write",
"evidence": {}
},
"claims": { <- I make a lot of claims too, but here are the few that look meaningful.
"idtyp": "user",
"ipaddr": "192.168.357.420",
"name": "Chris Farris", <- What does he know?
"http://schemas.microsoft.com/identity/claims/scope": "user_impersonation", <- No, I'm pretty sure that was me, not an impersonator
"http://schemas.microsoft.com/identity/claims/tenantid": "a83c74c3-7570-f74e-94c2-4bc9b3e0a510",
"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name": "chris@primeharbor.net",
"http://schemas.xmlsoap.org/ws/2005/05/identity/claims/upn": "chris@primeharbor.net",
...
}
},
"level": "Information",
"properties": {
"requestbody": "JSON-EncodedString", <- contains details of the request not in the Success ResultType
"eventCategory": "Administrative",
"entity": "/subscriptions/815322b7-f234-4156-96d1-927e59acd96b/providers/microsoft.insights/diagnosticSettings/logging",
"message": "microsoft.insights/diagnosticSettings/write",
"hierarchy": "a83c74c3-7570-f74e-94c2-4bc9b3e0a510/pht-sandbox/815322b7-f234-4156-96d1-927e59acd96b"
},
"tenantId": "a83c74c3-7570-f74e-94c2-4bc9b3e0a510"
}
{ <- This is a new event, lots of duplication removed
"RoleLocation": "Canada Central",
"category": "Administrative",
"resultType": "Success", <- This is really what you're looking for
"resultSignature": "Succeeded.OK", <- Same data, because they want to sell more storage
"durationMs": "1878",
"correlationId": "10019937-0818-4529-8c57-0f129d43be80",
"identity": {...},
"level": "Information",
"properties": {
"statusCode": "OK", <- One more time, because the extra 18 char help pays Satya's coffee.
"serviceRequestId": null,
"eventCategory": "Administrative",
"entity": "/subscriptions/815322b7-f234-4156-96d1-927e59acd96b/providers/microsoft.insights/diagnosticSettings/logging",
"message": "microsoft.insights/diagnosticSettings/write",
"hierarchy": "a83c74c3-7570-f74e-94c2-4bc9b3e0a510/pht-sandbox/815322b7-f234-4156-96d1-927e59acd96b"
},
"tenantId": "a83c74c3-7570-f74e-94c2-4bc9b3e0a510"
}
GCP
In Google Cloud Platform, audit logging is done by the Logging service. To capture or export your logs, you create a Log Router Sink or Log Sink to direct the logs to a Pub/Sub topic for ingestion into an SIEM, to BigQuery, or to a Logging or Cloud Storage Bucket.
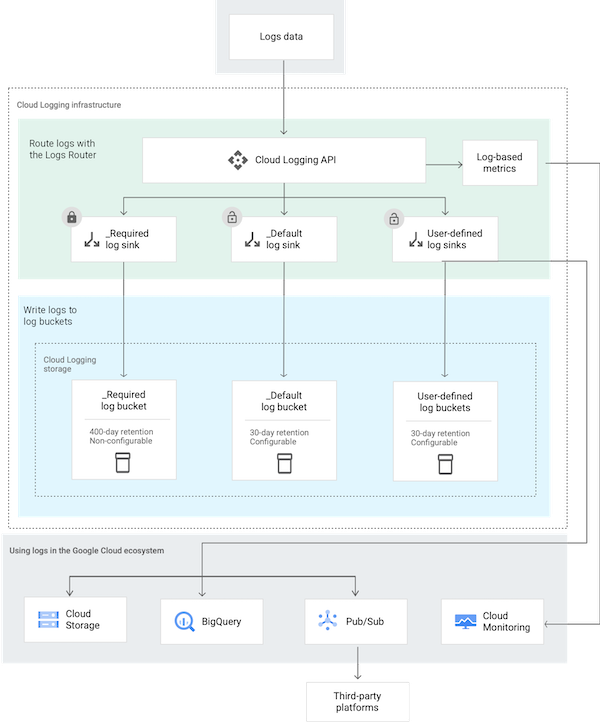
Common destinations for Cloud Logging:
- storage.googleapis.com/[BUCKET_ID]
- logging.googleapis.com/projects/[PROJECT_ID]/locations/[LOCATION_ID]/buckets/[BUCKET_ID]
- bigquery.googleapis.com/projects/[PROJECT_ID]/datasets/[DATASET_ID]
- pubsub.googleapis.com/projects/[PROJECT_ID]/topics/[TOPIC_ID]
The activity log is an Admin Activity audit log. Its payload is a JSON representation of the AuditLog type (cite):
{
"publish_time": 1705161139.743,
"data": {
"logName": "projects/logging-lo624-dp103/logs/cloudaudit.googleapis.com%2Factivity", <- Ending in activity means a mutating event
"protoPayload": {
"@type": "type.googleapis.com/google.cloud.audit.AuditLog", <- CloudPlane logging
"authenticationInfo": {
"principalEmail": "admin-chris@labs.pht.us" <- Who did it
},
"authorizationInfo": [
{
"granted": true,
"permission": "logging.buckets.update", <- what IAM Permission the action required
this is super useful for troubleshooting.
}
],
"methodName": "google.logging.v2.ConfigServiceV2.UpdateBucket", <- Action Performed
"request": {...},
"requestMetadata": {
"callerIp": "192.168.357.420", <-- From Where
"callerSuppliedUserAgent": "Mozilla/5.0 AppleWebKit...",
"destinationAttributes": {},
"requestAttributes": {...}
},
"resourceName": "projects/logging-lo624-dp103/locations/global/buckets/pht-labs-logging", <-- Against what resource
"serviceName": "logging.googleapis.com", <- Against which service
"status": {}
},
"receiveTimestamp": "2024-01-13T15:52:18.810579305Z",
"resource": {
"labels": {
"method": "google.logging.v2.ConfigServiceV2.UpdateBucket",
"project_id": "logging-lo624-dp103",
"service": "logging.googleapis.com"
},
"type": "audited_resource"
},
"severity": "NOTICE", <- Typically denotes read or write events. Read Events are INFO
"timestamp": "2024-01-13T15:52:18.228016503Z"
},
"attributes": {
"logging.googleapis.com/timestamp": "2024-01-13T15:52:18.228016503Z"
}
}
Splunk has a useful guide to querying GCP Audit Logs
Culture
There are several cultural differences between the different cloud providers.
While AWS and GCP leverage Python heavily for their official SDKs and documentation, Azure uses a mix of Powershell and Python (for their native CLI client az). The ability to write Powershell is critical for configuring Azure.
Whereas everything in AWS is available to all customers at the outset, GCP requires the customer to enable an API before use. This can lead to a fun set of errors when using a new project.
│ Error: Error creating KeyRing: googleapi: Error 403: Google Cloud KMS API has not been used in project 123456 before or it is disabled. Enable it by visiting https://console.developers.google.com/apis/api/cloudkms.googleapis.com/overview?project=123456, then retry. If you enabled this API recently, wait a few minutes for the action to propagate to our systems and retry.
Most AWS examples are implemented in CloudFormation, AWS’s native IaC language. Meanwhile, Google has embraced terraform and often provides terraform code examples in the console. Azure has its own native IaC Azure Resource Manager (ARM) templating language but often provides examples in Terraform.
Finally, the open-source ecosystem is much larger around AWS than for Azure of GCP. Free tools in Azure and GCP, like CSPM, are harder to come by and don’t have the same level of resource and misconfiguration coverage.
What are you going to do about it?
Chances are, your builders are using other clouds. The question is: do you know about it, and what will you do about it?
The second part of this post and my talk at HackCon is Minimal Viable Cloud Governance: How to go about ensuring you have a base foundation for alternate clouds so you don’t find yourself surrounded by shadow-clouds you don’t know about.
Notes
Eric Johnson’s Destroying Long-Lived Cloud Credentials with Workload Identity Federation