


In my last post I described how we improved our cloud security via the scorecards and spreadsheets. This post describes how we generate scorecards on an hourly basis using the basic building block of AWS.
The goal was to use native AWS services, with a secondary goal of avoiding the use of EC2 Instances that would need patching and other TLC. AWS is like Legos, they give you lots of parts and you have to put them together. The AWS services we used were:
- AWS Organizations
- AWS CloudFormation
- AWS Lambda
- Amazon CloudWatch
- AWS Step Functions
- Amazon Step Functions
- Amazon Simple Queue Service (SQS)
- Amazon Simple Notification Service (SNS)
- Amazon S3
- Amazon Elasticsearch Service
- AWS Trusted Advisor
The scorecards are built via two systems (each deployed via CloudFormation). Phase 1 is the inventory phase where we gather data from our 250+ AWS accounts spread across four payer accounts. Phase 2 we determine what resources in those accounts are non-compliant with our Cloud Security Standard.
Both systems are AWS Step Functions that fire off and trigger a large number of lambdas to do the work for each AWS account.
Inventory System
Our inventory system fires off every 30 minutes. It has a list of our four payer accounts and the name of the cross-account audit role it should assume. It assumes the role in each of the four payers to get the list of child accounts. These are cached in DynamoDB for use by other processes. The populate_accounts() function then publishes one message to an SNS topic with the account_id for each account. I’ve dubbed this model Spray-n-Pray because the step function uses SNS to fire off a bunch of lambda, but we don’t actually track the return information or individual success or failure.
Subscribed to that topic are a large number of lambda. Each lambda is responsible for inventorying a specific AWS service or resource we care about. Some examples are:
- S3 buckets
- CloudTrail
- IAM Users and Roles
- ECR Repositories
- EC2 Instances and Security groups
- ECS Clusters, Tasks and containers
- Route 53 Zones and Domains
- All ENIs in each VPC
- Secrets Manager Secrets
- AWS ElasticSearch domains
- VPCs
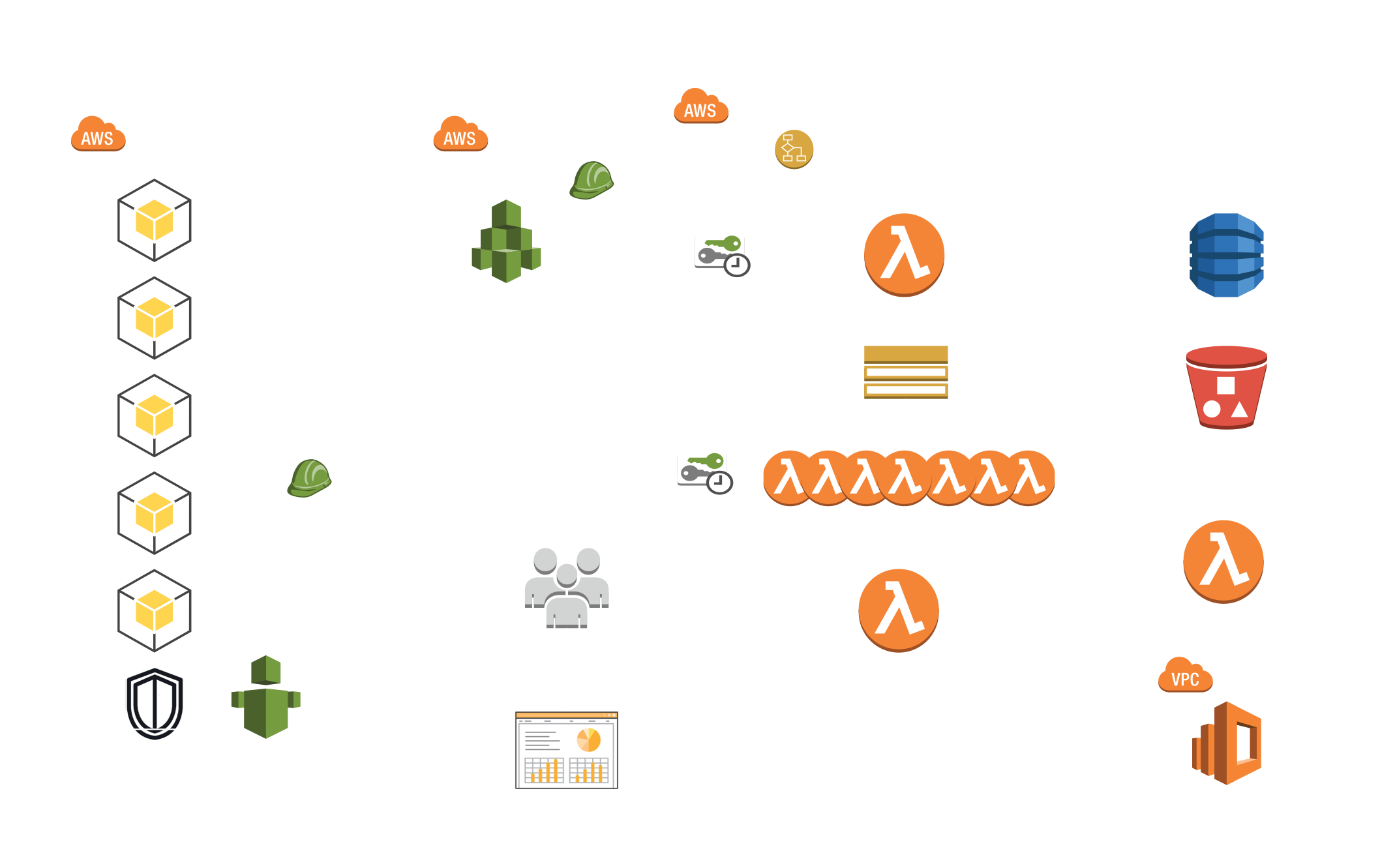
All of that resource data is stored in an S3 bucket. From there S3 notifications push the data into an ElasticSearch cluster, and our Splunk SEIM picks the data up to use as decoration for our CloudTrail, GuardDuty and other events.
One trick we adopted from Netflix’s SecurityMonkey project is that we capture any AWS account id we find in a trust policy and save that into our Account DynamoDB table. We can then identify who we’re trusting, decorate that entry with name and approval information. This gives us a quick and easy way to find unauthorized cross account relationships.
ScoreCards
The scorecard system uses the same building blocks as the inventory system. They run hourly and leverage the OpenPyXL python library to generate the excel files we mail to the account owners.
We determine what resources are non-compliant in several ways. We have some custom scripts that tell us if our required security tools are not deployed. We’ve modified CloudSploit to run as a lambda and assume a cross account role for many of our checks. The CloudSploit lambda is also subscribed to the inventory SNS topic so it runs constantly and dumps its output to json for consumption by the scorecard system.
The ScoreCards run in three phases.
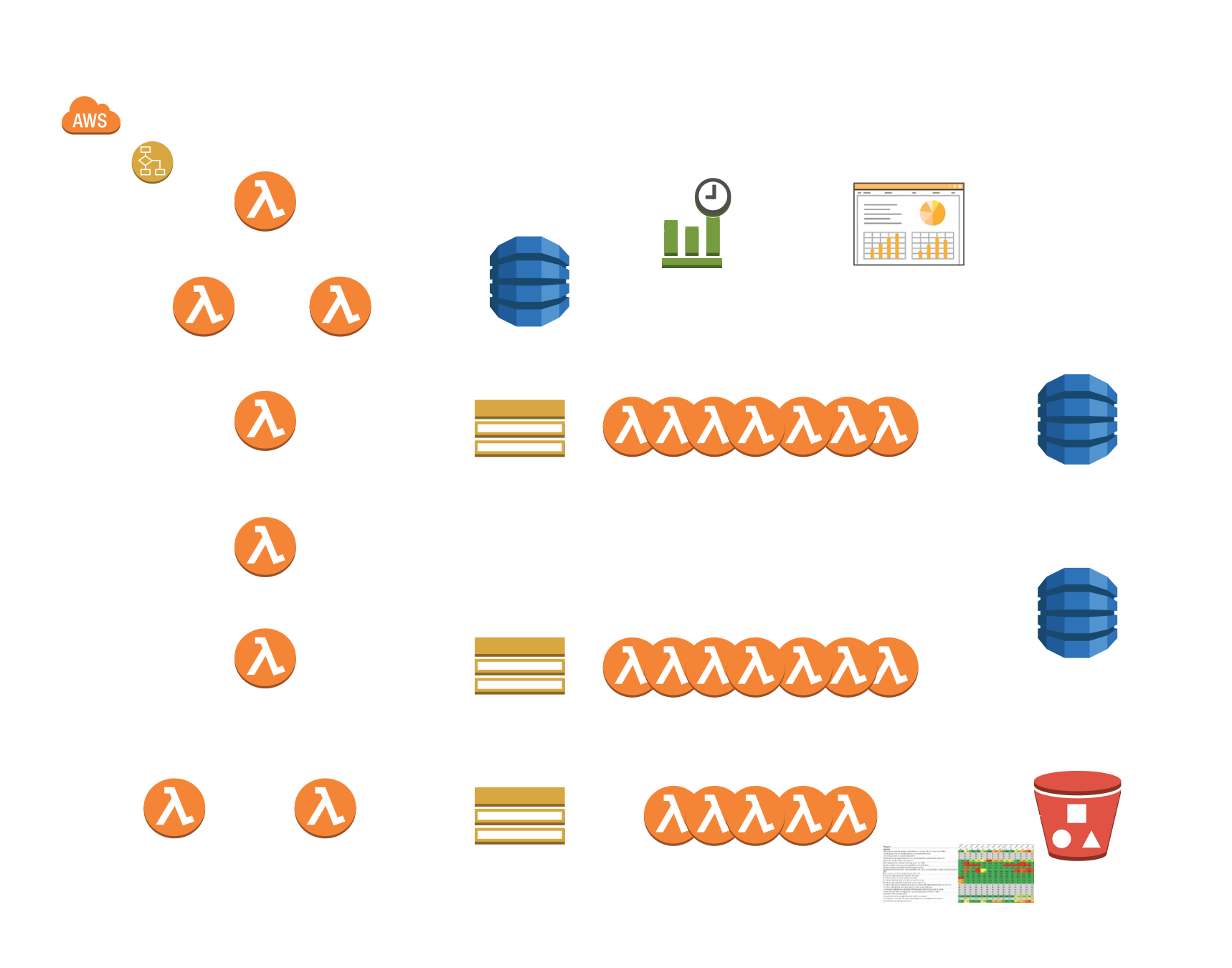
When we fire off the Step Function, it pulls the account list from DynamoDB. It then uses the same Spray-n-Pray method to determine which resources are non-compliant. Those resources are then saved to a table. Additionally we capture the number of non-compliant resources along with the total number of resources.
We then apply any risk exceptions (see below) before we trigger the score calculation phase. Different data sources have different scoring methods so we have 3-5 different lambda subscribed to the PhaseII SNS Topic. One message per AWS Account is published to that topic, and the calculated scores are saved back to DynamoDB. This is where the fourth grade math kicks in:
1-(NonCompliantResources / TotalResources)
This gives us a percentage of compliance.
The final phase generates the spreadsheets. We generate two sets of spreadsheets. One is individualized to each cloud account owner. This shows them their personal score, the risk-weighted (by requirement) score for all the accounts they’re responsible for, and the scores for each individual requirement by account. We then create tabs for each account with that account’s non-compliant resources. This way there is no guessing involved as to why they did not get 100%.
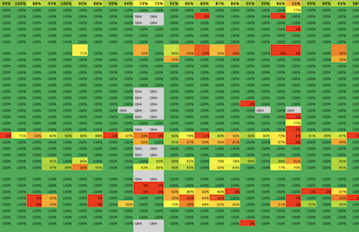 We also generate the enterprise wide scorecard. That scorecard has three tabs. The first tab shows all the AWS accounts and the score by requirement. The second tab list all of the accounts, the account’s overall score and current spend (which is pulled from CloudWatch Metrics Estimated bill). The final tab lists all of the executive owners and their scores. We risk weight the executive scores by AWS account spend. This leads us to the senior executive dashboard that is used to drive compliance. No VP wants a red box next to their name when the CISO, CTO or CFO is reviewing our cloud security.
We also generate the enterprise wide scorecard. That scorecard has three tabs. The first tab shows all the AWS accounts and the score by requirement. The second tab list all of the accounts, the account’s overall score and current spend (which is pulled from CloudWatch Metrics Estimated bill). The final tab lists all of the executive owners and their scores. We risk weight the executive scores by AWS account spend. This leads us to the senior executive dashboard that is used to drive compliance. No VP wants a red box next to their name when the CISO, CTO or CFO is reviewing our cloud security.
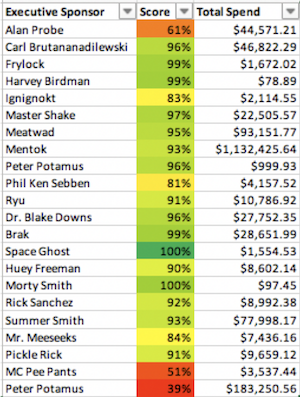
(Mentok the Mindtaker is bitcoin mining again)
Exceptions
A vital feature most security vulnerability products lack is the ability to integrate with a risk acceptance register. We all know that FTP is really bad, but there may be cases where that protocol is required. It is up to the business to decide if that is an acceptable risk, and up to the development team and the security team to work out compensating controls. A scorecard is not useful it if cannot reflect the fact that “yes, we’re being stupid here, but were going in eyes wide open and this box needs to be green”.
Ignoring accepted risk in these scorecards means that an account owner could legitimately have an 80% score with no ability to go higher. Always having a red box next to a requirement means that the technical team won’t look to see if a different resource is out of compliance or not. Real risk would hide behind accepted risk and vulnerabilities we didn’t know about would persist.
For us, the risk register is as simple as a SharePoint form. We capture the list of AWS accounts and Cloud Security Standard Requirements as lookup tables. We have an text box for AWS Resource ID. We export the risk register to json on an hourly basis via some Powershell magic. The scorecard system imports that data into DynamoDB at the start of each run. When we see a non-compliant resource that matches the resource-id, account-id and requirement, we grant credit for that in the scoring table and annotate the exception information in the non-compliant resources table. Exceptions have expiration dates which are captured in Sharepoint, so if the the expiration date is passed we still note the exception, but no longer give credit for that resource.
As a result, all accounts can theoretically be at 100%, either because there are no issues, or that the risk acceptance committee as agreed that the risk is acceptable and have granted an exception to the standard.
What’s next.
 I’ve been given approval to open source this under the project name Antiope. The inventory portion is about ready to release. Once that is done I’ll get the scorecard portion ported over. Check it out on github
I’ve been given approval to open source this under the project name Antiope. The inventory portion is about ready to release. Once that is done I’ll get the scorecard portion ported over. Check it out on github
Additionally, we are a multi-cloud company, and I’m drafting security standards for Azure and GCP. Since everything is API based, I intend for the Antiope framework to provide scorecards for Azure & GCP too.
[1]: CloudSploit has an open sourced scanning engine that has the best coverage of AWS services I’ve seen. They have a commercial service, but we just use the scanning engine.